
Hadiah ARC tetap tidak terkalahkan.
Ide-ide baru masih dibutuhkan.
Sistem o3 baru OpenAI – yang dilatih pada set Pelatihan Publik ARC-AGI-1 – telah mencapai terobosan 75,7% pada Evaluasi Semi-Pribadi yang ditetapkan pada batas komputasi $10k di papan peringkat publik yang kami nyatakan. Konfigurasi o3 komputasi tinggi (172x) mencetak skor 87,5%.
Ini adalah peningkatan fungsi langkah yang mengejutkan dan penting dalam kemampuan AI, yang menunjukkan kemampuan adaptasi tugas baru yang belum pernah terlihat sebelumnya dalam model keluarga GPT. Sebagai konteksnya, ARC-AGI-1 membutuhkan waktu 4 tahun untuk beralih dari 0% dengan GPT-3 pada tahun 2020 menjadi 5% pada tahun 2024 dengan GPT-4o. Semua intuisi tentang kemampuan AI perlu diperbarui untuk o3.
Misi ARC Prize melampaui tolok ukur pertama kami: menjadi Bintang Utara menuju AGI. Dan kami sangat gembira dapat bekerja sama dengan tim OpenAI dan pihak lainnya pada tahun depan untuk terus merancang tolok ukur AGI generasi berikutnya yang tahan lama.
ARC-AGI-2 (format yang sama – terverifikasi mudah bagi manusia, lebih sulit bagi AI) akan diluncurkan bersamaan dengan ARC Prize 2025. Kami berkomitmen untuk menyelenggarakan kompetisi Hadiah Utama hingga solusi sumber terbuka berefisiensi tinggi dengan skor 85% tercipta. .
Baca terus untuk laporan pengujian selengkapnya.
Hasil OpenAI o3 ARC-AGI
Kami menguji o3 terhadap dua kumpulan data ARC-AGI:
- Evaluasi Semi-Pribadi: 100 tugas pribadi yang digunakan untuk menilai overfitting
- Evaluasi Publik: 400 tugas publik
Berdasarkan arahan OpenAI, kami menguji pada dua tingkat komputasi dengan ukuran sampel variabel: 6 (efisiensi tinggi) dan 1024 (efisiensi rendah, komputasi 172x).
Inilah hasilnya.
| Mengatur | Tugas | Efisiensi | Skor | Biaya Ritel | Sampel | Token | Biaya/Tugas | Waktu/Tugas (menit) |
|---|---|---|---|---|---|---|---|---|
| Setengah swasta | 100 | Tinggi | 75,7% | $2.012 | 6 | 33M | $20 | 1.3 |
| Setengah swasta | 100 | Rendah | 87,5% | – | – | – | – | – |
| Publik | 400 | Tinggi | 82,8% | $6.677 | 6 | 111M | $17 | T/A |
| Publik | 400 | Rendah | 91,5% | – | – | – | – | — |
- Catatan: OpenAI telah meminta agar kami tidak mempublikasikan biaya komputasi yang tinggi. Jumlah komputasinya kira-kira 172x konfigurasi komputasi rendah.
Karena anggaran inferensi variabel, efisiensi (misalnya, biaya komputasi) kini menjadi metrik yang diperlukan saat melaporkan kinerja. Kami telah mendokumentasikan total biaya dan biaya per tugas sebagai proksi awal untuk efisiensi. Sebagai sebuah industri, kita perlu mencari tahu metrik apa yang paling baik melacak efisiensinamun secara terarah, biaya adalah titik awal yang kuat.
Skor efisiensi tinggi sebesar 75,7% berada dalam aturan anggaran ARC-AGI-Pub (biaya <$10k) dan oleh karena itu memenuhi syarat sebagai posisi pertama di papan peringkat publik!
Skor efisiensi rendah sebesar 87,5% cukup mahal, namun tetap menunjukkan bahwa kinerja pada tugas-tugas baru memang meningkat seiring dengan peningkatan komputasi (setidaknya hingga tingkat ini.)
Meskipun biaya per tugas cukup besar, angka-angka ini bukan hanya hasil dari penerapan komputasi brute force pada benchmark. Model o3 baru OpenAI mewakili lompatan maju yang signifikan dalam kemampuan AI untuk beradaptasi dengan tugas-tugas baru. Hal ini bukan sekadar peningkatan bertahap, namun merupakan terobosan nyata, yang menandai perubahan kualitatif dalam kemampuan AI dibandingkan dengan keterbatasan LLM sebelumnya. o3 adalah sistem yang mampu beradaptasi dengan tugas-tugas yang belum pernah dihadapi sebelumnya, dan bisa dibilang mendekati kinerja tingkat manusia dalam domain ARC-AGI.
Tentu saja, tindakan umum seperti itu membutuhkan biaya yang besar, dan belum cukup ekonomis: Anda dapat membayar manusia untuk menyelesaikan tugas ARC-AGI dengan biaya sekitar $5 per tugas (kami tahu, kami telah melakukannya), dan hanya menghabiskan satu sen dolar dalam satu tugas. energi. Sementara itu o3 membutuhkan $17-20 per tugas dalam mode komputasi rendah. Namun kinerja biaya kemungkinan akan meningkat secara dramatis dalam beberapa bulan dan tahun ke depan, sehingga Anda harus merencanakan agar kemampuan ini dapat bersaing dengan pekerjaan manusia dalam jangka waktu yang cukup singkat.
Peningkatan o3 atas seri GPT membuktikan bahwa arsitektur adalah segalanya. Anda tidak dapat melakukan lebih banyak komputasi pada GPT-4 dan mendapatkan hasil ini. Sekadar meningkatkan hal-hal yang kami lakukan dari tahun 2019 hingga 2023 – menggunakan arsitektur yang sama, melatih versi yang lebih besar dengan lebih banyak data – tidaklah cukup. Kemajuan selanjutnya adalah tentang ide-ide baru.
Jadi apakah itu AGI?
ARC-AGI berfungsi sebagai tolok ukur penting untuk mendeteksi terobosan-terobosan tersebut, menyoroti kekuatan generalisasi dengan cara yang tidak dapat dilakukan oleh tolok ukur yang jenuh atau tidak terlalu menuntut. Namun, penting untuk dicatat bahwa ARC-AGI bukanlah tes asam untuk AGI – seperti yang telah kami ulangi puluhan kali pada tahun ini. Ini adalah alat penelitian yang dirancang untuk memusatkan perhatian pada masalah paling menantang yang belum terpecahkan dalam AI, sebuah peran yang telah dipenuhi dengan baik selama lima tahun terakhir.
Lulus ARC-AGI tidak berarti mencapai AGI, dan faktanya, menurut saya o3 belum termasuk AGI. o3 masih gagal dalam beberapa tugas yang sangat mudah, menunjukkan perbedaan mendasar dengan kecerdasan manusia.
Selain itu, poin data awal menunjukkan bahwa benchmark ARC-AGI-2 yang akan datang masih akan memberikan tantangan yang signifikan terhadap o3, dan berpotensi menurunkan skornya hingga di bawah 30% bahkan pada komputasi tinggi (sementara manusia cerdas masih dapat memperoleh skor di atas 95%). tanpa pelatihan). Hal ini menunjukkan kemungkinan berkelanjutan untuk menciptakan tolok ukur yang menantang dan tidak jenuh tanpa harus bergantung pada pengetahuan domain pakar. Anda akan mengetahui bahwa AGI ada di sini ketika upaya membuat tugas yang mudah bagi manusia biasa namun sulit bagi AI menjadi mustahil.
Apa bedanya o3 dibandingkan model lama?
Mengapa skor o3 jauh lebih tinggi daripada o1? Dan mengapa skor o1 jauh lebih tinggi daripada GPT-4o? Saya rasa rangkaian hasil ini memberikan poin data yang sangat berharga untuk upaya berkelanjutan dalam mencapai AGI.
Model mental saya untuk LLM adalah mereka bekerja sebagai gudang program vektor. Saat diminta, mereka akan mengambil program yang dipetakan oleh prompt Anda dan “mengeksekusinya” pada input yang ada. LLM adalah cara untuk menyimpan dan mengoperasionalkan jutaan program mini yang berguna melalui paparan pasif terhadap konten buatan manusia.
Paradigma “menghafal, mengambil, menerapkan” ini dapat mencapai tingkat keterampilan yang sewenang-wenang dalam tugas-tugas yang sewenang-wenang dengan data pelatihan yang sesuai, namun paradigma ini tidak dapat beradaptasi dengan hal-hal baru atau mengambil keterampilan baru dengan cepat (artinya tidak ada kecerdasan cair yang berperan). di sini.) Hal ini terlihat dari rendahnya kinerja LLM pada ARC-AGI, satu-satunya tolok ukur yang dirancang khusus untuk mengukur kemampuan beradaptasi terhadap hal-hal baru – GPT-3 mendapat skor 0, GPT-4 mendapat skor mendekati 0, GPT-4o mendapat skor 5%. Meningkatkan model-model ini hingga batas yang mungkin dicapai tidak menghasilkan angka ARC-AGI yang mendekati apa yang dapat dicapai oleh pencacahan kasar dasar beberapa tahun yang lalu (hingga 50%).
Untuk beradaptasi dengan hal baru, Anda memerlukan dua hal. Pertama, Anda memerlukan pengetahuan – serangkaian fungsi atau program yang dapat digunakan kembali. LLM memiliki lebih dari cukup. Kedua, Anda memerlukan kemampuan untuk menggabungkan kembali fungsi-fungsi ini ke dalam program baru ketika menghadapi tugas baru – program yang memodelkan tugas yang ada. Sintesis program. LLM sudah lama tidak memiliki fitur ini. Seri o model memperbaikinya.
Untuk saat ini, kami hanya dapat berspekulasi tentang cara kerja o3 secara spesifik. Namun mekanisme inti o3 tampaknya merupakan pencarian dan eksekusi program bahasa alami dalam ruang token – pada waktu pengujian, model mencari ruang Rantai Pemikiran (CoTs) yang mungkin menggambarkan langkah-langkah yang diperlukan untuk menyelesaikan tugas, dengan cara yang mungkin tidak terlalu baik. berbeda dengan pencarian pohon Monte-Carlo gaya AlphaZero. Dalam kasus o3, pencarian mungkin dipandu oleh semacam model evaluator. Untuk diketahui, Demis Hassabis mengisyaratkan kembali wawancara Juni 2023 bahwa DeepMind telah meneliti ide ini – pekerjaan ini sudah lama dilakukan.
Jadi sementara LLM generasi tunggal berjuang dengan hal-hal baru, o3 mengatasinya dengan membuat dan melaksanakan programnya sendiri, di mana program itu sendiri (CoT) menjadi artefak rekombinasi pengetahuan. Meskipun ini bukan satu-satunya pendekatan yang layak untuk rekombinasi pengetahuan waktu pengujian (Anda juga dapat melakukan pelatihan waktu pengujian, atau mencari di ruang laten), pendekatan ini mewakili kecanggihan terkini berdasarkan angka ARC-AGI baru ini. .
Secara efektif, o3 mewakili suatu bentuk pencarian program yang dipandu pembelajaran mendalam. Model melakukan penelusuran waktu pengujian pada ruang “program” (dalam hal ini, program bahasa alami – ruang CoT yang mendeskripsikan langkah-langkah untuk menyelesaikan tugas yang ada), dipandu oleh pembelajaran mendalam sebelumnya (LLM dasar) . Alasan mengapa menyelesaikan satu tugas ARC-AGI dapat menghabiskan puluhan juta token dan menghabiskan biaya ribuan dolar adalah karena proses pencarian ini harus mengeksplorasi sejumlah besar jalur melalui ruang program – termasuk penelusuran mundur.
Namun ada dua perbedaan signifikan antara apa yang terjadi di sini dan apa yang saya maksudkan ketika saya sebelumnya menjelaskan “pencarian program yang dipandu pembelajaran mendalam” sebagai jalur terbaik untuk mencapai AGI. Yang terpenting, program yang dihasilkan oleh o3 adalah instruksi bahasa alami (untuk “dieksekusi” oleh LLM) daripada program simbolik yang dapat dieksekusi. Ini berarti dua hal. Pertama, mereka tidak dapat melakukan kontak dengan kenyataan melalui pelaksanaan dan evaluasi langsung terhadap tugas – sebaliknya, mereka harus dievaluasi kesesuaiannya melalui model lain, dan evaluasi tersebut, jika tidak memiliki landasan seperti itu, mungkin akan menjadi salah jika dijalankan di luar distribusi. Kedua, sistem tidak dapat secara mandiri memperoleh kemampuan untuk menghasilkan dan mengevaluasi program-program ini (seperti sistem seperti AlphaZero yang dapat belajar memainkan permainan papan sendiri.) Sebaliknya, sistem bergantung pada data CoT yang dihasilkan manusia dan diberi label ahli.
Belum jelas apa batasan sebenarnya dari sistem baru ini dan seberapa jauh skalanya. Kami memerlukan pengujian lebih lanjut untuk mengetahuinya. Terlepas dari itu, kinerja saat ini mewakili pencapaian yang luar biasa, dan konfirmasi yang jelas bahwa pencarian waktu pengujian yang dipandu oleh intuisi pada ruang program adalah paradigma yang kuat untuk membangun sistem AI yang dapat beradaptasi dengan tugas-tugas yang sewenang-wenang.
Apa yang terjadi selanjutnya?
Pertama-tama, replikasi o3 sumber terbuka, yang difasilitasi oleh kompetisi ARC Prize pada tahun 2025, akan sangat penting untuk memajukan komunitas riset. Analisis menyeluruh terhadap kekuatan dan keterbatasan o3 diperlukan untuk memahami perilaku penskalaannya, sifat potensi hambatannya, dan mengantisipasi kemampuan apa yang mungkin dihasilkan oleh pengembangan lebih lanjut.
Selain itu, ARC-AGI-1 kini sudah jenuh – selain skor baru o3, faktanya adalah bahwa sejumlah besar solusi Kaggle dengan komputasi rendah kini dapat memperoleh skor 81% pada evaluasi pribadi.
Kami akan meningkatkan standar dengan versi baru – ARC-AGI-2 – yang telah dikembangkan sejak tahun 2022. Versi ini menjanjikan penyetelan ulang besar-besaran dari versi tercanggih. Kami ingin hal ini mendorong batas-batas penelitian AGI dengan evaluasi yang keras dan bersinyal tinggi yang menyoroti keterbatasan AI saat ini.
Pengujian awal ARC-AGI-2 kami menunjukkan bahwa ini akan berguna dan sangat menantang, bahkan untuk o3. Dan tentu saja tujuan ARC Prize adalah menghasilkan a efisiensi tinggi Dan sumber terbuka solusi untuk memenangkan Hadiah Utama. Saat ini kami bermaksud meluncurkan ARC-AGI-2 bersamaan dengan ARC Prize 2025 (perkiraan peluncuran: akhir Q1).
Ke depannya, ARC Prize Foundation akan terus membuat tolok ukur baru untuk memfokuskan perhatian para peneliti pada masalah tersulit yang belum terpecahkan menuju AGI. Kami telah mulai mengerjakan benchmark generasi ketiga yang sepenuhnya berangkat dari format ARC-AGI 2019 dan menggabungkan beberapa ide baru yang menarik.
Terlibat: Analisis Sumber Terbuka
Hari ini, kami juga merilis tugas komputasi tinggi berlabel o3 dan memerlukan bantuan Anda untuk menganalisisnya. Secara khusus, kami sangat penasaran dengan ~9% rangkaian tugas Evaluasi Publik yang o3 tidak dapat selesaikan, bahkan dengan banyak komputasi, namun mudah dilakukan oleh manusia.
Kami mengundang komunitas untuk membantu kami menilai karakteristik tugas yang terselesaikan dan belum terselesaikan.
Agar ide Anda mengalir, berikut 3 contoh tugas yang tidak dapat diselesaikan dengan komputasi tinggi o3.
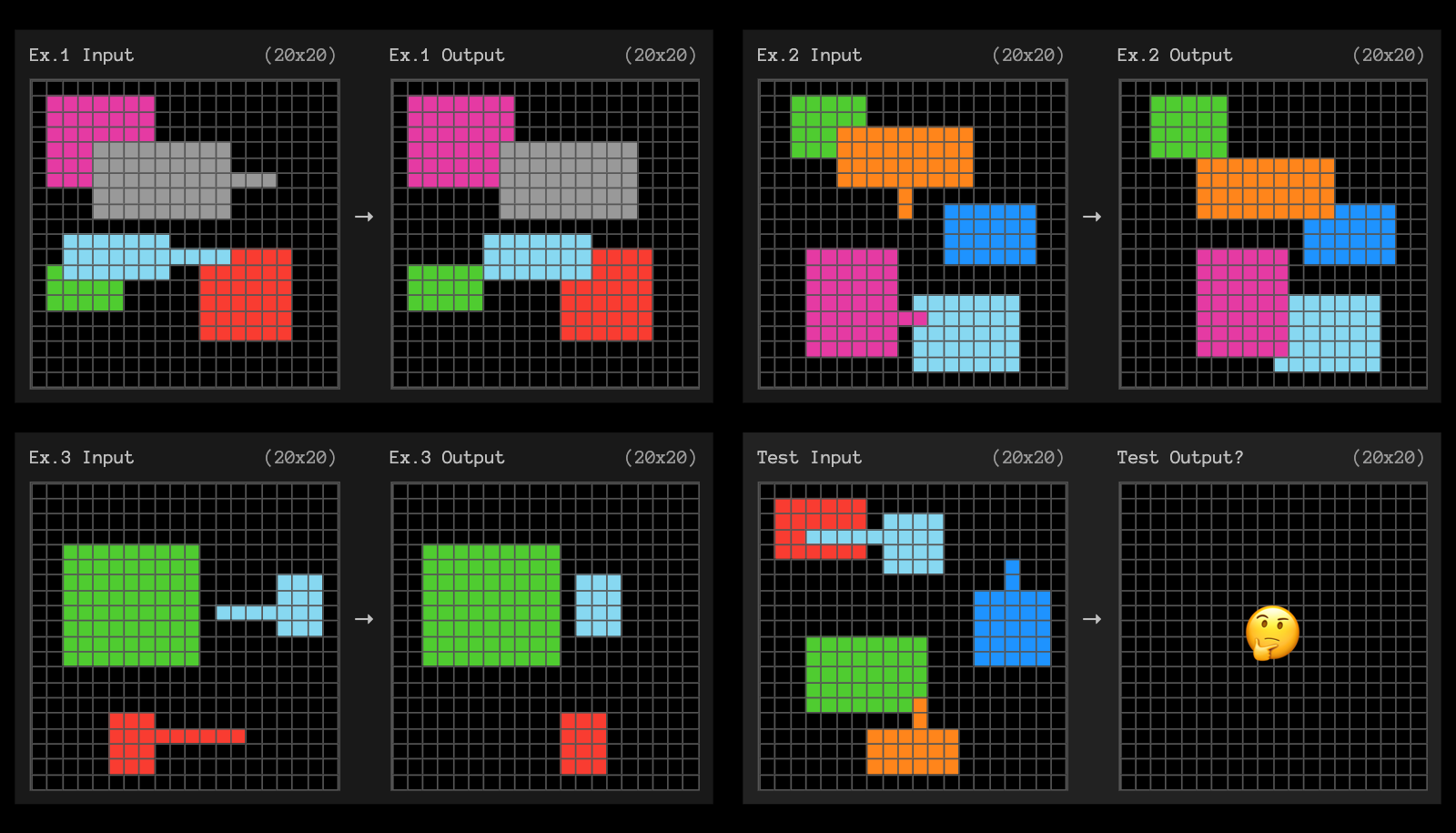
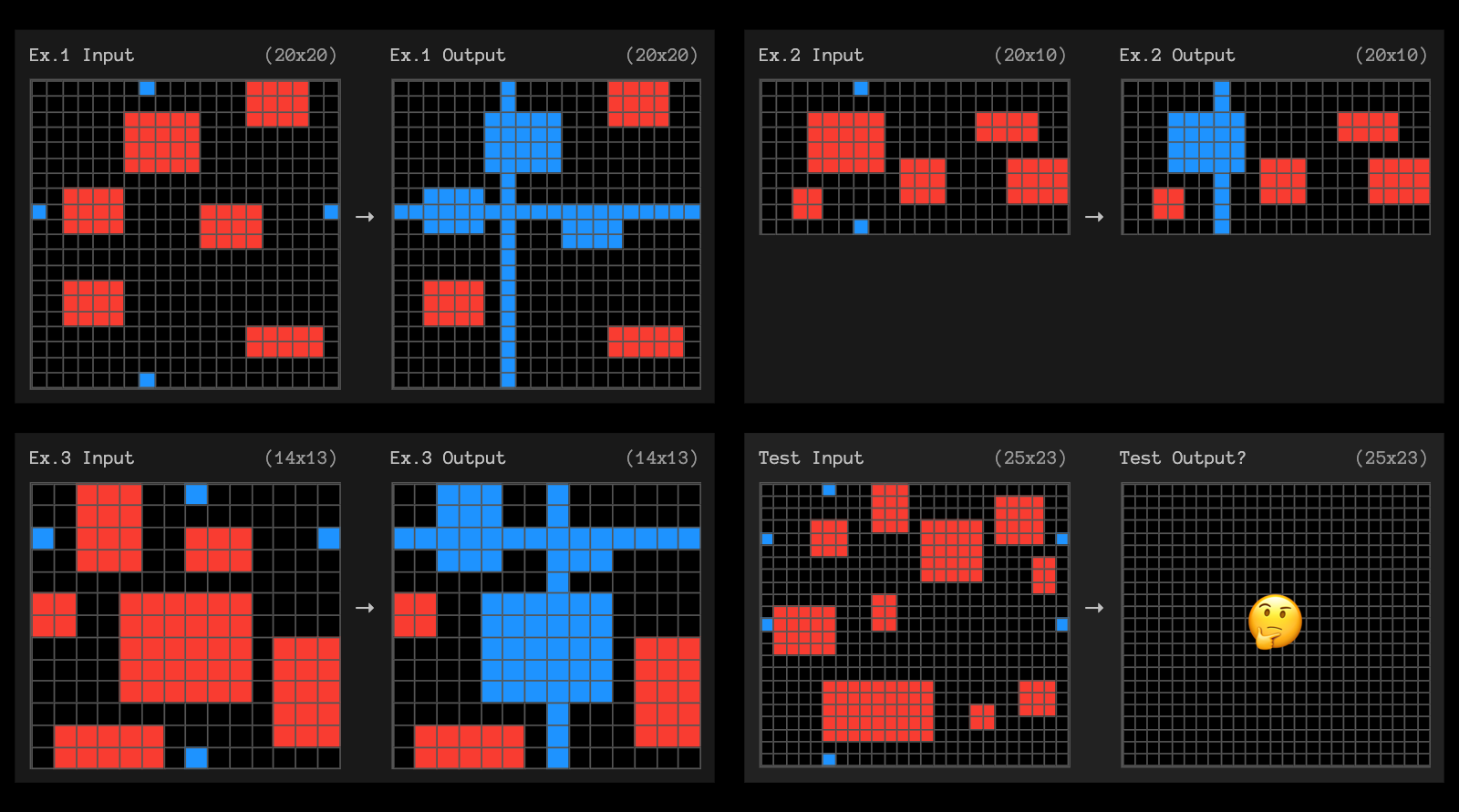

Lihat kumpulan lengkap data pengujian o3 kami.
Kami juga telah membuat saluran baru di Discord kami yang diberi nama oai-analysis dan kami ingin mendengar analisis dan wawasan Anda di sana. Atau tandai kami di X/Twitter @arcprize.
Kesimpulan
Singkatnya – o3 mewakili lompatan maju yang signifikan. Kinerjanya pada ARC-AGI menyoroti terobosan nyata dalam kemampuan beradaptasi dan generalisasi, dengan cara yang tidak dapat dibuat secara eksplisit oleh tolok ukur lain.
o3 memperbaiki keterbatasan mendasar paradigma LLM – ketidakmampuan untuk menggabungkan kembali pengetahuan pada waktu ujian – dan hal ini dilakukan melalui bentuk pencarian program bahasa alami yang dipandu LLM. Ini bukan sekadar kemajuan bertahap; ini adalah wilayah baru, dan memerlukan perhatian ilmiah yang serius.










{kind=link}