9 Agustus 2023
•
Komunitas MLC
TL;DR
MLC-LLM memungkinkan untuk mengkompilasi LLM dan menerapkannya pada GPU AMD menggunakan ROCM dengan kinerja kompetitif. Lebih khusus lagi, AMD Radeon™ RX 7900 XTX memberikan 80% kecepatan NVIDIA® GeForce RTX™ 4090 dan 94% kecepatan NVIDIA® GeForce RTX™ 3090Ti untuk Llama2-7B/13B. Selain ROCm, dukungan Vulkan kami memungkinkan kami menggeneralisasi penerapan LLM ke perangkat AMD lainnya, misalnya SteamDeck dengan AMD APU.
Latar belakang
Ada banyak solusi inferensi LLM sejak berkembangnya LLM sumber terbuka. Sebagian besar solusi inferensi berkinerja didasarkan pada CUDA dan dioptimalkan untuk GPU NVIDIA. Sementara itu, dengan tingginya permintaan akan ketersediaan komputasi, memberikan dukungan pada kelas akselerator perangkat keras yang lebih luas akan bermanfaat. AMD adalah salah satu kandidat potensial.
Pembahasan Hardware dan Software
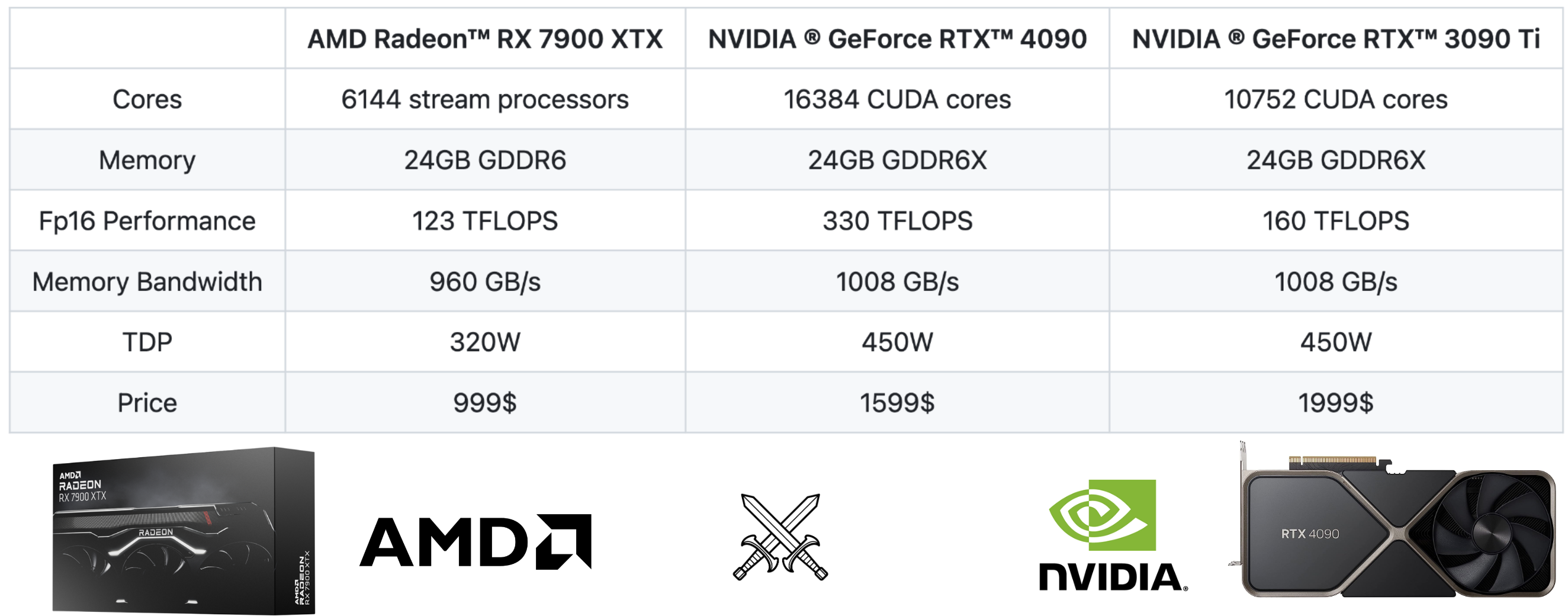
Dari perbandingan spesifikasi, kita dapat melihat bahwa AMD RX 7900 XTX cocok dengan NVIDIA RTX 4090 dan RTX 3090 Ti.
- Semuanya memiliki memori 24GB, yang berarti dapat memuat model dengan ukuran yang sama.
- Semua memiliki bandwidth memori yang serupa.
- 4090 memiliki performa FP16 2x lebih baik dibandingkan 7900 XTX, sedangkan 3090 Ti memiliki performa FP16 1,3x lebih baik dibandingkan 7900 XTX. Inferensi LLM yang sensitif terhadap lantensi sebagian besar terikat pada memori, sehingga kinerja FP16 tidak menjadi hambatan di sini.
- RX 7900 XTX 40% lebih murah dibandingkan RTX 4090.
Lebih sulit membandingkan harga 3090Ti dengan generasi sebelumnya. Kami meletakkannya di sini sebagai titik referensi untuk memberikan informasi lebih lanjut. Pada tingkat tinggi, kita dapat menemukan bahwa AMD 7900 XTX sebanding dengan RTX 3090 Ti dari perspektif spesifikasi perangkat keras.
Perangkat keras belum tentu menjadi alasan mengapa AMD tertinggal di masa lalu. Kesenjangan utama disebabkan oleh kurangnya dukungan perangkat lunak dan optimalisasi model yang relevan. Ada dua faktor dalam ekosistem yang mulai membawa perubahan:
- AMD sedang mencoba mengejar ketinggalan dengan investasi di tumpukan ROCm.
- Teknologi baru seperti kompilasi pembelajaran mesin membantu mengurangi biaya keseluruhan dari dukungan perangkat lunak yang lebih universal di seluruh backend.
Dalam postingan ini, kami melihat secara mendalam seberapa baik kinerja GPU AMD dibandingkan dengan solusi CUDA berperforma tinggi pada GPU NVIDIA saat ini.
Kompilasi Pembelajaran Mesin untuk ROCm
Apa itu kompilasi pembelajaran mesin (MLC). Kompilasi pembelajaran mesin adalah teknologi baru yang mengkompilasi dan mengotomatiskan optimalisasi beban kerja pembelajaran mesin. Daripada membuat kernel spesifik untuk setiap backend seperti ROCm atau CUDA, solusi MLC secara otomatis menghasilkan kode untuk backend yang berbeda. Di sini kami memanfaatkan MLC-LLM, solusi berbasis kompilasi ML yang menawarkan penerapan universal berkinerja tinggi untuk LLM. MLC-LLM dibangun di atas Apache TVM Unity, tumpukan kompilasi pembelajaran mesin yang menawarkan pengembangan produktif yang mengutamakan Python dan penerapan universal. MLC-LLM menghadirkan kinerja tercanggih untuk berbagai macam backend, termasuk CUDA, Metal, ROCm, Vulkan, dan OpenCL, yang mencakup GPU kelas server hingga seluler (iPhone dan Android). Pada tingkat tinggi, kerangka kerja ini memungkinkan pengguna mengambil model bahasa terbuka dan mengompilasinya dengan alur kerja berbasis Python, termasuk API untuk mengubah grafik komputasi, mengoptimalkan tata letak dan penjadwalan kernel GPU, dan menerapkannya secara asli pada platform yang diminati.

MLC untuk GPU dan APU AMD. Ada beberapa kemungkinan cara untuk mendukung GPU AMD: ROCm, OpenCL, Vulkan, dan WebGPU. Tumpukan ROCm adalah apa yang baru-baru ini didorong oleh AMD dan memiliki banyak blok penyusun terkait yang mirip dengan tumpukan CUDA. Vulkan adalah standar grafis terbaru dan menawarkan dukungan terluas di seluruh perangkat GPU. WebGPU adalah standar web terbaru yang memungkinkan komputasi dijalankan di browser web. Meskipun ada banyak kemungkinan cara, hanya sedikit solusi perangkat lunak ML yang dibuat untuk solusi selain CUDA, sebagian besar disebabkan oleh biaya teknis untuk mereplikasi tumpukan untuk model pemrograman perangkat keras atau GPU baru. Kami mendukung pembuatan kode otomatis tanpa harus membuat ulang kernel GPU untuk masing-masing cara dan memberikan dukungan untuk semua cara ini. Meskipun demikian, performanya masih bergantung pada seberapa bagus runtime GPU tingkat rendah dan ketersediaannya di setiap platform. Kami memilih ROCm untuk Radeon 7900 XTX dan Vulkan untuk APU Steamdeck. Kami menemukan bahwa tumpukan ROCm berfungsi dengan baik. Berkat jalur pengembangan produktif berbasis Python di TVM unity, kami menghabiskan beberapa jam lagi untuk lebih menghadirkan versi yang dioptimalkan. Kami melakukan hal-hal berikut untuk menghadirkan dukungan ROCm:
- Gunakan kembali seluruh pipeline MLC untuk target yang ada (seperti CUDA dan Metal), termasuk perencanaan memori, fusi operator, dll.
- Gunakan kembali ruang pengoptimalan kernel GPU generik yang ditulis di TVM TensorIR dan targetkan ulang ke GPU AMD.
- Gunakan kembali aliran pembuatan kode ROCm TVM yang menghasilkan kernel ROCm tingkat rendah melalui LLVM.
- Terakhir, ekspor kode yang dihasilkan sebagai pustaka bersama atau statis yang dapat dipanggil oleh CLI, Python, dan REST API.
Tolok ukur dengan Paket MLC Python
Kami membandingkan Llama 2 7B dan 13B dengan kuantisasi 4-bit. Dan kami mengukur kinerja decoding dengan menetapkan satu token cepat dan menghasilkan 512 token. Semua hasil diukur untuk inferensi batch tunggal.

Untuk kinerja inferensi batch tunggal, dapat mencapai 80% dari kecepatan NVIDIA 4090 dengan dirilisnya ROCm 5.6.
Catatan tentang perbandingannya: Seberapa kuat baseline CUDA kita? Sejauh pengetahuan kami, ini adalah yang tercanggih untuk melakukan tugas ini. Kami yakin masih ada ruang untuk perbaikan, misalnya melalui optimalisasi perhatian yang lebih baik. Segera setelah pengoptimalan tersebut diterapkan di MLC, kami mengantisipasi peningkatan angka AMD dan NVIDIA. Jika pengoptimalan seperti itu hanya diterapkan di sisi NVIDIA, kesenjangannya akan meningkat dari 20% menjadi 30%. Oleh karena itu, kami menyarankan untuk menempatkan bilah kesalahan 10% ketika melihat angka-angka di sini
Cobalah sendiri
Kami menyediakan roda bawaan dan instruksi untuk mereproduksi hasil kami di perangkat Anda sendiri. Untuk menjalankan benchmark tersebut, pastikan Anda memiliki GPU AMD dengan ROCm 5.6 atau lebih tinggi yang berjalan di Linux. Ikuti instruksinya Di Sini untuk menginstal paket MLC bawaan dengan ROCm diaktifkan: Jalankan skrip Python di bawah ini yang menggunakan paket MLC kami untuk mereproduksi angka kinerja:
from mlc_chat import ChatModule
# Create a ChatModule instance that loads from `./dist/prebuilt/Llama-2-7b-chat-hf-q4f16_1`
cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1")
# Run the benchmarks
output = cm.benchmark_generate("Hi", generate_length=512)
print(f"Generated text:n{output}n")
print(f"Statistics: {cm.stats()}")
# Reset the chat module by
# cm.reset_chat()
MLC-LLM juga menyediakan CLI yang memungkinkan Anda mengobrol dengan model secara interaktif. Untuk ROCm perlu membangun CLI dari sumber. Silakan ikuti instruksinya Di Sini untuk membangun CLI dari sumber.
Berjalan di SteamDeck menggunakan Vulkan dengan Unified Memory
Mari kita lihat juga rangkaian perangkat AMD yang lebih luas, lebih khusus lagi, SteamDeck yang dilengkapi dengan AMD APU. Meskipun VRAM GPU yang tersedia di ROCm dibatasi hingga 4GB di BIOS, driver Mesa Vulkan memiliki dukungan kuat yang memungkinkan buffer melampaui batas tersebut menggunakan memori terpadu hingga 16GB, yang cukup untuk menjalankan Llama-7B terkuantisasi 4bit.
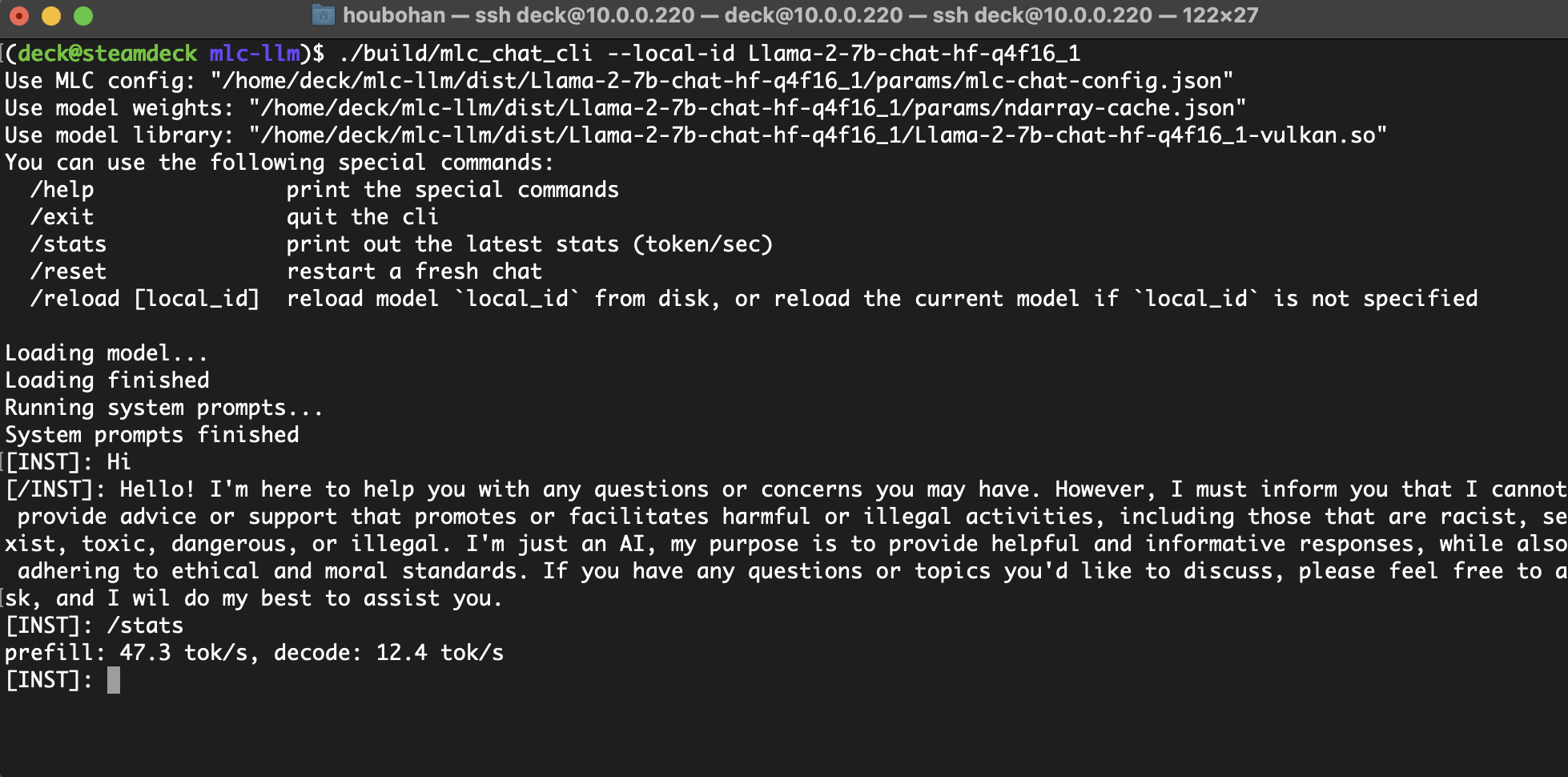
Hasil ini menjelaskan bagaimana spektrum perangkat AMD yang luas dapat didukung untuk konsumen yang lebih beragam.
Diskusi dan Pekerjaan Masa Depan
Ketersediaan perangkat keras telah menjadi masalah mendesak di era AI generatif. Kompilasi ML dapat membantu dengan menghadirkan penerapan universal berkinerja tinggi di seluruh backend perangkat keras. Berdasarkan bukti yang disajikan, dengan harga dan ketersediaan yang tepat, menurut kami GPU AMD dapat mulai berguna untuk inferensi LLM.
Studi kami saat ini berfokus pada GPU tingkat konsumen. Berdasarkan pengalaman kami sebelumnya, pengoptimalan MLC untuk model GPU konsumen biasanya dapat digeneralisasikan ke GPU cloud (misalnya dari RTX 4090 hingga A100 dan A10g). Kami yakin bahwa solusi ini dapat diterapkan pada GPU AMD dan NVIDIA kelas cloud dan konsumen, dan juga akan memperbarui studi kami setelah kami memiliki akses ke lebih banyak GPU. Kami juga mendorong komunitas untuk membangun solusi selain alur penerapan universal MLC.
Postingan ini adalah bagian dari upaya berkelanjutan yang menghadirkan penerapan universal berkinerja tinggi melalui MLC. Kami juga secara aktif mengerjakan beberapa bidang yang dapat menggeneralisasi penelitian kami.
- Aktifkan dukungan batching dan multi-GPU;
- Integrasi dengan ekosistem PyTorch;
- Memberdayakan lebih banyak kuantisasi dan arsitektur model;
- Menghadirkan lebih banyak pengoptimalan otomatis pada lebih banyak backend perangkat keras.
Kesimpulan terakhir kami adalah bahwa rekayasa sistem pembelajaran mesin merupakan masalah yang berkelanjutan. NVIDIA masih memimpin dalam bidang ini dengan inovasi berkelanjutan, dan kami mengantisipasi perubahan dengan perangkat keras baru seperti H100 dan, yang lebih penting, evolusi perangkat lunak. Jadi pertanyaan kuncinya bukan hanya tentang membangun solusi yang tepat saat ini, tetapi juga bagaimana mengejar ketertinggalan dan terus menghadirkan rekayasa ML ke platform baru. Produktivitas dalam teknik pembelajaran mesin adalah kuncinya di sini. Berkat alur pengembangan kompilasi ML yang mengutamakan Python, kami mendapatkan dukungan yang dioptimalkan untuk ROCm dalam beberapa jam. Kami mengantisipasi pendekatan terkait menjadi lebih berguna saat kami mengeksplorasi lebih banyak ide untuk menerapkan penerapan universal dan memecahkan masalah ketersediaan perangkat keras.
Tautan
Silakan merujuk ke kami halaman proyek untuk panduan terperinci tentang cara mencoba penerapan MLC LLM. Kode sumber MLC LLM tersedia di situs resmi kami Repositori GitHub. Anda juga dipersilakan untuk bergabung Saluran Perselisihan untuk diskusi lebih lanjut.
Pengakuan
Keseluruhan proyek MLC hanya mungkin terwujud berkat ekosistem sumber terbuka tempat kami berdiri. Kami ingin terus mengembangkan dan mendukung komunitas ML sumber terbuka. Kami ingin mengucapkan terima kasih kepada komunitas Apache TVM dan pengembang compiler TVM Unity. Anggota komunitas ML sumber terbuka membuat model ini tersedia untuk umum. Komunitas PyTorch dan Hugging Face membuat model ini dapat diakses. Kami ingin mengucapkan terima kasih kepada tim di balik RedPajama, Dolly, Vicuna, SentencePiece, LLaMA, dan Alpaca. Kami juga ingin mengucapkan terima kasih kepada komunitas OpenCL, Vulkan, C++, Python, dan Rust yang memungkinkan proyek ini.










{kind=link}