
Model kecerdasan buatan (AI) baru saja hadir mencapai hasil tingkat manusia pada tes yang dirancang untuk mengukur “kecerdasan umum”.
Pada tanggal 20 Desember, sistem o3 OpenAI mendapat skor 85% pada Tolok ukur ARC-AGIjauh di atas skor terbaik AI sebelumnya yaitu 55% dan setara dengan skor rata-rata manusia. Ia juga mendapat nilai bagus pada tes matematika yang sangat sulit.
Menciptakan kecerdasan umum buatan, atau AGI, adalah tujuan semua laboratorium penelitian AI besar. Pada pandangan pertama, OpenAI tampaknya telah membuat langkah signifikan menuju tujuan ini.
Meski skeptisisme masih ada, banyak peneliti dan pengembang AI merasa ada sesuatu yang baru saja berubah. Bagi banyak orang, prospek AGI kini tampak lebih nyata, mendesak, dan lebih dekat dari yang diperkirakan. Apakah mereka benar?
Generalisasi dan kecerdasan
Untuk memahami arti dari hasil o3, Anda perlu memahami apa yang dimaksud dengan tes ARC-AGI. Dalam istilah teknis, ini adalah pengujian “efisiensi sampel” sistem AI dalam beradaptasi dengan sesuatu yang baru – berapa banyak contoh situasi baru yang perlu dilihat sistem untuk mengetahui cara kerjanya.
Sistem AI seperti ChatGPT (GPT-4) tidak terlalu efisien dalam pengambilan sampel. Ia “dilatih” pada jutaan contoh teks manusia, membangun “aturan” probabilistik tentang kombinasi kata mana yang paling mungkin terjadi.
Hasilnya cukup bagus dalam tugas-tugas umum. Ini buruk dalam tugas-tugas yang tidak biasa, karena memiliki lebih sedikit data (lebih sedikit sampel) tentang tugas-tugas tersebut.
Sampai sistem AI dapat belajar dari sejumlah kecil contoh dan beradaptasi dengan sampel yang lebih efisien, sistem tersebut hanya akan digunakan untuk pekerjaan yang sangat berulang dan kegagalan yang sesekali dapat ditoleransi.
Kemampuan untuk secara akurat menyelesaikan permasalahan yang sebelumnya tidak diketahui atau permasalahan baru dari sampel data yang terbatas dikenal sebagai kapasitas untuk menggeneralisasi. Hal ini secara luas dianggap sebagai elemen penting, bahkan mendasar, dari kecerdasan.
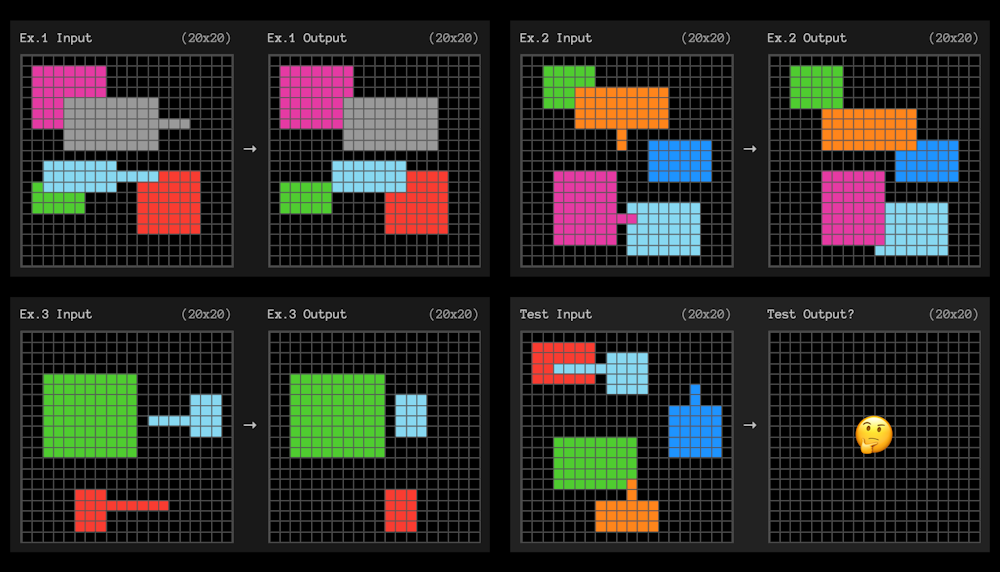
Grid dan pola
Tolok ukur ARC-AGI menguji sampel adaptasi yang efisien menggunakan masalah kotak kecil seperti di bawah ini. AI perlu menemukan pola yang mengubah grid di sebelah kiri menjadi grid di sebelah kanan.
Hadiah ARC
Setiap pertanyaan memberikan tiga contoh untuk dipelajari. Sistem AI kemudian perlu mencari tahu aturan yang “menggeneralisasi” dari tiga contoh hingga contoh keempat.
Ini sangat mirip dengan tes IQ yang terkadang Anda ingat di sekolah.
Aturan dan adaptasi yang lemah
Kami tidak tahu persis bagaimana OpenAI melakukannya, namun hasilnya menunjukkan model o3 sangat mudah beradaptasi. Dari beberapa contoh saja, ditemukan aturan-aturan yang dapat digeneralisasikan.
Untuk mengetahui suatu pola, kita tidak boleh membuat asumsi yang tidak perlu, atau lebih spesifik dari yang seharusnya. Di dalam teorijika Anda dapat mengidentifikasi aturan “terlemah” yang melakukan apa yang Anda inginkan, maka Anda telah memaksimalkan kemampuan Anda untuk beradaptasi dengan situasi baru.
Apa yang kami maksud dengan aturan terlemah? Definisi teknisnya rumit, namun aturan yang lebih lemah biasanya merupakan definisi yang rumit dijelaskan dalam pernyataan yang lebih sederhana.
Dalam contoh di atas, ekspresi aturan dalam bahasa Inggris yang sederhana dapat berupa: “Bentuk apa pun yang memiliki garis menonjol akan berpindah ke ujung garis tersebut dan ‘menutupi’ bentuk lain yang tumpang tindih dengannya.”
Mencari rantai pemikiran?
Meskipun kita belum mengetahui bagaimana OpenAI mencapai hasil ini, sepertinya mereka tidak sengaja mengoptimalkan sistem o3 untuk menemukan aturan yang lemah. Namun, untuk berhasil dalam tugas ARC-AGI, mereka harus menemukannya.
Kita tahu bahwa OpenAI dimulai dengan versi model o3 untuk tujuan umum (yang berbeda dari kebanyakan model lainnya, karena model ini dapat menghabiskan lebih banyak waktu untuk “berpikir” tentang pertanyaan sulit) dan kemudian melatihnya secara khusus untuk pengujian ARC-AGI.
Peneliti AI Perancis, Francois Chollet, yang merancang benchmark tersebut, percaya o3 menelusuri “rantai pemikiran” berbeda yang menjelaskan langkah-langkah untuk menyelesaikan tugas. Ia kemudian akan memilih yang “terbaik” berdasarkan aturan yang didefinisikan secara longgar, atau “heuristik”.
Hal ini “tidak berbeda” dengan cara sistem AlphaGo Google menelusuri berbagai kemungkinan rangkaian gerakan untuk mengalahkan juara dunia Go.
Anda dapat menganggap rantai pemikiran ini seperti program yang sesuai dengan contoh. Tentu saja, jika seperti AI Go-playing, maka diperlukan heuristik, atau aturan longgar, untuk menentukan program mana yang terbaik.
Mungkin ada ribuan program berbeda yang tampaknya sama validnya. Heuristik tersebut dapat berupa “pilih yang terlemah” atau “pilih yang paling sederhana”.
Namun, jika seperti AlphaGo maka mereka hanya memiliki AI yang membuat heuristik. Ini adalah proses untuk AlphaGo. Google melatih model untuk menilai rangkaian gerakan yang berbeda sebagai lebih baik atau lebih buruk dibandingkan yang lain.
Yang masih belum kita ketahui
Pertanyaannya kemudian, apakah ini benar-benar mendekati AGI? Jika ini adalah cara kerja o3, maka model dasarnya mungkin tidak lebih baik dari model sebelumnya.
Konsep yang dipelajari model dari bahasa mungkin tidak lagi cocok untuk digeneralisasi dibandingkan sebelumnya. Sebaliknya, kita mungkin hanya melihat “rantai pemikiran” yang lebih umum ditemukan melalui langkah-langkah tambahan dalam pelatihan heuristik yang dikhususkan untuk pengujian ini. Buktinya, seperti biasa, ada di pudingnya.
Hampir segala sesuatu tentang o3 masih belum diketahui. OpenAI membatasi pengungkapan pada beberapa presentasi media dan pengujian awal kepada segelintir peneliti, laboratorium, dan lembaga keamanan AI.
Untuk benar-benar memahami potensi o3 akan memerlukan kerja keras, termasuk evaluasi, pemahaman tentang distribusi kapasitasnya, seberapa sering gagal dan seberapa sering berhasil.
Ketika o3 akhirnya dirilis, kita akan memiliki gagasan yang lebih baik tentang apakah ia dapat beradaptasi seperti manusia pada umumnya.
Jika hal ini benar, maka hal ini akan memberikan dampak ekonomi yang besar dan revolusioner, serta membuka era baru percepatan kecerdasan yang bisa dikembangkan sendiri. Kami memerlukan tolok ukur baru untuk AGI itu sendiri dan pertimbangan serius mengenai cara pengelolaannya.
Jika tidak, ini akan tetap menjadi hasil yang mengesankan. Namun, kehidupan sehari-hari akan tetap sama.![]()
Michael Timotius BennettMahasiswa PhD, Sekolah Komputasi, Universitas Nasional Australia Dan Pilih PerrierRekan Peneliti, Pusat Teknologi Kuantum yang Bertanggung Jawab Stanford, Universitas Stanford
Artikel ini diterbitkan ulang dari Percakapan di bawah lisensi Creative Commons. Baca artikel asli.


 terhenti di bursa transfer, tapi Milan pasti membutuhkan bala bantuan")





{kind=link}
{kind=link}